
Everything You Need to Know About JavaScript SEO

Just launched a dynamic website? Kudos to you! It could be your best sales move yet, presenting your best face to online prospects and convincing them to buy into your story.
But if you have used JavaScript for your website, it is important to remember that it can thwart your intentions by preventing your site, or at least a part of it, from getting indexed on Google and other search engines thus stopping it from appearing in the search results.
How will your prospects visit your website if it’s nowhere in the search results?
That’s why you need to ensure that your use of JavaScript isn’t impeding your SEO.
But before you start asking how to do that, let’s understand what JavaScript is and how it can impact your search rankings. We will share some useful tips and then explain how to fix common JavaScript SEO mistakes.
What is JavaScript?
JavaScript is a key component of modern web pages, the others being HTML (Hypertext Markup Language) and CSS (Cascading Style Sheets).
There are two ways in which engineers use JavaScript on web pages—embedding it in HTML within script tags, or inserting references to it. A gamut of JavaScript libraries and frameworks are currently in use, including jQuery, EmberJS, and AngularJS.
Asynchronous JavaScript combines with XML to enable web applications to have seamless communication with the server without interfering with the page that appears on the browser.
Async JavaScript code would allow other functions to run while it’s functioning. XML is deployed for passing data. AJAX is the popular term for this technology.Google Maps is a good example of AJAX in action.
Why JavaScript is Important

JavaScript is the means of creating powerful applications that are dynamic in the true sense of the word. However, no website can succeed unless it is fully accessible to search engine bots.
Though JavaScript handles bots well, it is important to ensure your script does not obstruct search engine crawlers, preventing the proper indexing of your pages. If this happens, your pages won’t appear in the search results.
Search engine bots process JavaScript web apps in three phases—crawling, rendering, and indexing.
You need to work with SEO professionals in all these phases to make your JavaScript-backed web applications searchable via Google.
Understanding the Process
When a Googlebot visits a web page, it first checks whether you’ve allowed crawling by reading the robots.txt file or the meta robots tag. If this file carries instructions to skip the page, Googlebot will abort the task.
The classic bot approach of making an HTTP request and fetching URL works efficiently for server-side rendered pages.
However, many JavaScript pages may be using the app shell model and the initial HTML may not contain the actual content.
In this scenario, the Googlebot would need to execute JavaScript before it can find the actual page content generated by the script.
The bot would then parse the rendered HTML for links and queue the URLs discovered for crawling. Rendered HTML is used for indexing the page.
Now let’s find out how we can optimize web pages for search engines:
Recheck Robots.txt and Meta Robots Tag
Before introducing the website, check your robots.txt file and meta robots tag to make sure someone hasn’t blocked the bots accidently.
Many sites use JavaScript to append a meta robots tag to a page or alter its content. You can change the meta robots tag with JavaScript to facilitate indexing of the web page when an API call returns content.
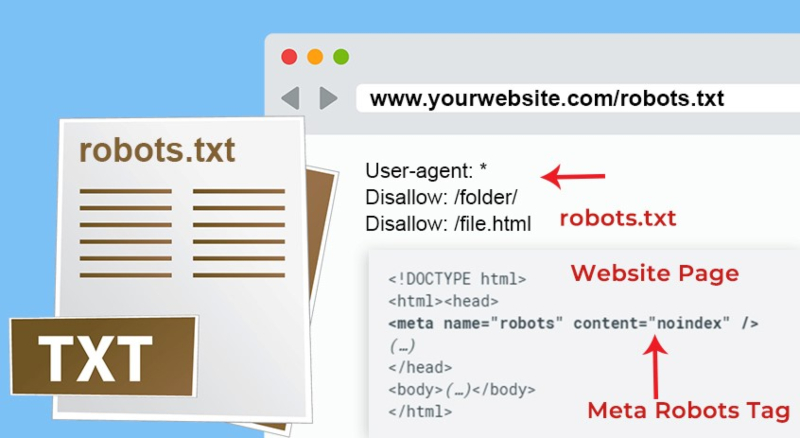
If you’re not sure when to use the robots.txt file and meta robots tags, here is a tip. The .txt file works best for blocking an entire section of websites, while meta tags are used for disallowing particular pages.
All major search engines like Google, Yahoo!, Bing, Baidu, and Yandex support robots meta tag values like index, noindex, follow, nofollow, etc.
You may also issue different instructions to various search engines. For this purpose, you may put in the value of the content attribute to the intended search engine such as Googlebot.
Be careful as search engine bots will simply ignore instructions that they’re unable to understand.
Use HTTP Status Codes to Interact with Bots
Bots use HTTP status codes to determine what has gone wrong during the crawling process.
Use a meaningful status code to convey to bots if a certain web page should not be crawled or indexed, such as a 401 code for pages requiring a login.
HTTP status codes can also inform bots if a certain page has been shifted to a new URL, instructing it to index the page accordingly.
Here’s a list of meanings of various HTTP codes for your reference:
- 401/403: Page unavailable due to permission issues
- 301/302: Page now available at a new URL
- 404/410: Page unavailable now
- 5xx:Issues on the server side
Ensure Your Code is Compatible
When writing JavaScript code, you need to ensure it’s compatible with browsers of all hues. These browsers use several APIs and your code should be able to hook with most, if not all APIs.
Your SEO professionals should be aware of the limitations of these bots regarding various features. At the least, your code should be written keeping in mind the limitations of major search engines like Google and Bing.
Your team should be able to identify and resolve JavaScript issues that may be hindering indexing or display of your page on search engines. In some cases, the code may be blocking specific content on JavaScript-powered pages.
There is always some difference between your perception and what the crawlers are accessing and rendering with respect to your content.
To find out how Googlebot is viewing your page, you could use the URL inspection tool in Search Console.
Use Unique Titles and Snippets
Use JavaScript to give unique titles and snippets that help users identify the page. Here is some advice for managing your titles:
- Every page on your site should have a specific title.
- Make page titles descriptive and concise.
- Avoid boilerplate titles such as ‘cheap products for sale.
- Avoid any inkling of keyword stuffing.
- Use titles to provide some additional information about your website.
The Google algorithm creates snippets directly from the page content. The search engine may show different content for different searches, depending on the user’s search.
There are two techniques to suggest content for these snippets—structured data and meta description tags.
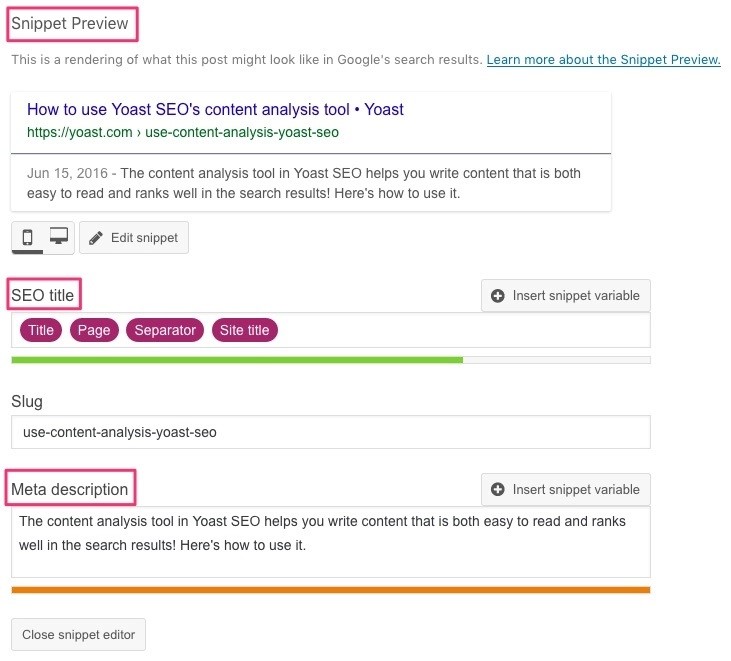
Structured data [See above image] will help Google understand the page better. It may also use meta tags for presenting a snippet if it decides appropriate content is available there.
Try Lazy-Loading of Images
Images take a toll on your bandwidth and performance. A solution to this issue comes in the form of lazy-loading which involves loading images later and that too in a search-friendly manner.
However, it is important to ensure it’s done correctly or you may inadvertently end up hiding content from the search engine. Use a JavaScript library that supports loading of content when it enters the viewport.
If you favor an infinite scroll experience for your viewers, implement a mechanism to support paginated loading. It enables your users to share and re-engage with your content. Use the History API to update the URL when your system facilitates dynamic loading of content.
How to Fix Common JavaScript SEO Mistakes
Now that you’re aware of how to optimize JavaScript-powered web pages for search engines, let’s find out how to fix common JavaScript SEO errors. You should be able to quickly identify and resolve JavaScript issues that may be preventing rendering of your web pages using this guide.
Expecting a Bot to Index Content Requiring User Permission
Googlebot will ignore any content that requires users’ consent. Googlebot and its Web Rendering Service (WRS) clear local storage, HTTP cookies, and session storage data across page loads, so you cannot rely on data persistence to serve content.
Googlebot doesn’t support WebGL. If you’re using WebGL to render photo effects in the browser, deploy server-side rendering to pre-render the photo effects.
Struggling to Ensure Web Components are Search-Friendly
You may resolve this by putting your content into light DOM (Document Object Model) whenever possible.
Light DOM resides outside the component's shadow DOM and the markup is written by a user of your component.
Shadow DOM defines the component’s internal structure, scoped CSS, and encapsulates the implementation details.
These techniques eliminate the brittleness of building web apps emanating from the global nature of HTML, CSS, and JavaScript.
For example, when putting a new HTML id/class to use, it may cause conflict with an existing element on the page.
There may be unexpected bugs, style selectors may go awry, and CSS specificity may become a problem. Using light and shadow DOMs will help you take care of these issues.
Not Testing Websites for Mobile-Friendly Features
Mobile-friendliness is a key feature of successful websites, yet many fail to test it before release.
Google offers a website where you can paste the URL in the provided space, click ‘Analyze,’ and wait for a few seconds to find out how mobile-friendly your site is.
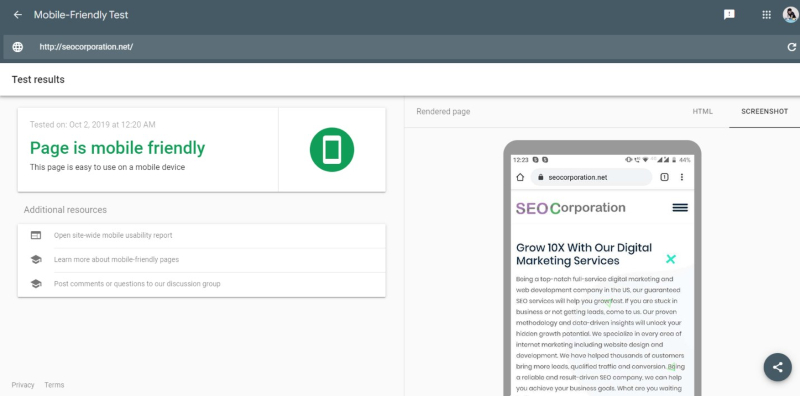
You may also use mobile-friendly test tools offered by independent service providers.
Summing Up
Search engine bots are designed to crawl and index web content in the optimum manner, yet they could stumble for a number of reasons and one of them is JavaScript.
The incorrect or imprecise use of JavaScript could prevent Google crawlers from seeing your web page as a user perceives them, leading to bad SEO.
The best way to ensure that JavaScript on your page is easily accessible to Google is through meticulous testing.
As the site owner, eventually it is up to you to ensure that your web pages are SEO-friendly so that you can derive maximum mileage out of your investment.
A string of tools are available to assist you in your goal of creating a website that search engines love. That said, your SEO professional’s skills and experience play a big role as well.
Posted by Vishal Vivek

Related Posts

A business website plays a critical role in how customers discover, evaluate, and interact with a brand.

Job hunting still devours your evenings—tweaking résumés, re-entering work history, clicking Apply on repeat.

Lost your iPhone? Well, it can be a pretty scary experience, but we promise you that not all hope is lost.

Real-time applications are changing the way we interact with digital platforms, providing instant updates and smooth experiences.
In the world of JavaScript programming, asynchronous operations are a fundamental concept that every developer should grasp. Asynchronous programming allows your code to perform time-consuming tasks, such as making HTTP requests or reading files, without blocking the execution of the rest of your...

WordPress is the backbone of over 40% of websites on the internet, making it the most popular content management system (CMS) globally.








{kind=link}
{kind=link}
Comments
comments powered by Disqus